Blog


Gli aspetti positivi nella scelta e nell’utilizzo di architetture a microservizi sono innumerevoli, dalla maggiore resilienza alla scalabilità implicita e la facilità di sviluppo. È innegabile però che questa tipologia di architettura risulti essere più complessa se paragonata, ad esempio, con una classica architettura monolitica suddivisa in layers.

L’aumento della complessità deriva dalla necessità di andare a progettare e sviluppare logiche e componenti specifici per la gestione dell’architettura rispetto allo sviluppo core dell’applicazione. Pensiamo ad esempio alla necessità di introdurre un API gateway per il routing verso i microservizi, all’uso di orchestratori e più in generale alla necessità di una analisi approfondita del dominio dei dati e del loro partizionamento.
Questa complessità è evidentemente soprattutto nelle fasi iniziali del progetto, la fase di startup di una classica applicazione monolitica è infatti decisamente più lineare rispetto ad una applicazione basata su microservizi. D’altro canto, la situazione è differente a regime, in una architettura a microservizi, lo sviluppo della singola funzionalità è molto più veloce.
Sistemi distribuiti e CAP Theorem
Per comprendere quali sono le caratteristiche di una architettura a microservizi e quali sono quindi le accortezze da tenere a mente nella loro progettazione è fondamentale conoscere alcuni dei concetti chiave dei sistemi distribuiti. Un sistema distribuito, per sua natura, non è mai completamente sincrono, ovvero non è sempre possibile fissare un upper bound nei tempi di comunicazione tra i differenti nodi del sitema. Nella realtà i sistemi distribuiti sono classificati come parzialmente sincroni, ovvero che alternano periodi nei quali sono sincroni rispetto ad altri nei quali sono asincroni. Uno dei teoremi più importanti è il Brewer Theorem, conosciuto più comunemente come il CAP Theorem, ovvero l’acronimo delle tre proprietà: Consistency, Availability, Partion tolerance.

Consistency significa la garanzia che ogni nodo in un sistema distribuito restituisca lo stesso dato e che questo sia aggiornato. L’availability è un concetto matematico e corrisponde alla probabilità che il sistema sia funzionante, in altre parole che ogni richiesta riceva una risposta. La partition tolerance, ovvero la tolleranza a partizioni di rete, significa che il sistema, nella sua totalità, continui a funzionare nonostante la presenza di partizioni, cioè la presenza di nodi non raggiungibili. Il teorema dimostra come è impossibile per un sistema distribuito garantire contemporaneamente tutte e tre le proprietà descritte.
L’intersezione delle diverse proprietà definisce le differenti tipologie di sistema e la scelta è chiaramente dipendente dal contesto applicativo.
Partizionamento dei dati: CQRS
Un altro aspetto fondamentale per progettare correttamente un’architettura di microservizi è la necessità di rendere indipendenti i dati su cui ogni microservizio andrà ad interagire. Progettare una corretta suddivisione del dominio dei dati della nostra applicazione è di fatto mandatorio.
𝗖𝗼𝗺𝗺𝗮𝗻𝗱 𝗮𝗻𝗱 𝗤𝘂𝗲𝗿𝘆 𝗥𝗲𝘀𝗽𝗼𝗻𝘀𝗶𝗯𝗶𝗹𝗶𝘁𝘆 𝗦𝗲𝗴𝗿𝗲𝗴𝗮𝘁𝗶𝗼𝗻 (𝗖𝗤𝗥𝗦) è un pattern che separa i modelli per la lettura e la scrittura dei dati.
Questo pattern si basa sostanzialmente sue due premesse: la prima è che staticamente le operazioni in lettura sono maggiori rispetto alle operazioni in scrittura; la seconda è che per evitare conflitti nelle transazioni, un database dovrebbe essere utilizzato solo da un solo servizio. In altre parole, ogni microservizio che compone l’architettura dovrebbe accedere alla sua base dati. CQRS si adatta perfettamente alle architetture a microservizi grazie alla sua capacità intrinseca di scalare e alla gestione implicita della concorrenza. D’altra parte, non è sempre banale applicare questo pattern, che certamente richiede una fase di analisi funzionale approfondita del dominio dei dati.
Rimuovere le dipendenze: Bulkhead pattern
Uno degli errori più comuni nella progettazione di architetture di microservizi è quello di creare una catena di chiamate interdipendenti tra i servizi. Queste catene di dipendenze tra i servizi riducono drasticamente la disponibilità dell’intero sistema, questo perché un guasto di un qualsiasi servizio invocato nelle chiamate causerà un guasto dell’intera catena.
Per evitare queste situazioni è buona norma utilizzare il pattern denominato 𝗕𝘂𝗹𝗸𝗵𝗲𝗮𝗱 per disaccoppiare le dipendenze tra i servizi e isolando l’elemento critico, ovvero l’elemento che presenta una elevata dipendenza. Identificato l’elemento critico si procede alla trasformazione dello stesso in un pool di servizi. Utilizzare questo pattern previene la propagazione degli errori e aumenta la resilienza dell’intero sistema.
Aumentare la resilienza: Circuit Breaker pattern
Ad eccezione delle comunicazioni front-end tra il client e il primo livello di microservizi, si consiglia di utilizzare una comunicazione asincrona tra i microservizi interni all’architettura. In caso di errori non transitori, ovvero errori che sono generalmente per loro natura temporanei, uno schema retry potrebbe non essere sufficiente ed è quindi preferibile un paradigma di fail fast. Questo perchè nel caso di errori non transitori, ripetere in modo indefinito una richiesta porterebbe ad ulteriore degrado dello stato del sistema.
Il pattern 𝗖𝗶𝗿𝗰𝘂𝗶𝘁 𝗕𝗿𝗲𝗮𝗸𝗲𝗿 impedisce a un’applicazione di eseguire un’operazione con probabilità minime di successo. Il funzionamento è basato sull’utilizzo di tre stati logici: Closed: in questo stato le richieste possono passare, poiché non sono stati rilevati errori o timeout. Open: in questo stato tutte le richieste vengono temporaneamente rifiutate per un determinato periodo di tempo. Questo per tentare di ripristinare il servizio in errore. Half-open: questo stato segue sempre lo stato Open ma solo un numero limitato di richieste potrà passare, se falliscono si tornerà allo stato Open mentre se avranno successo presumiamo che l’anomalia sia stata ripristinata e si passerà all stato Closed. Questo pattern permette di aumentare la resilienza dell’interno sistema evitando la propagazione del guasto.
Ridurre la chattiness: Gateway Aggregation pattern
Come accennato precedentemente, l’errore più comune nella progettazione di architetture a microservizi è quello di creare una catena di interdipendenza logica tra diverse entità. Tuttavia può capitare che il front-end o in generale il client che fruisce delle funzionalità esposte debba effettuare chiamate multiple verso i servizi di back-end.
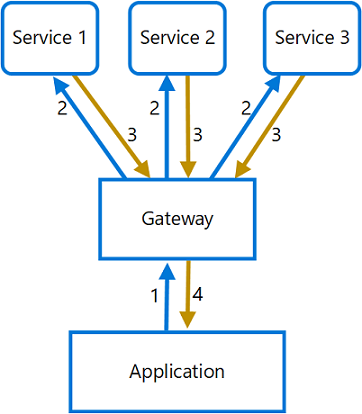
In questo caso, l’applicazione si basa evidentemente su differenti servizi per eseguire un’unica attività attraverso uno scambio di messaggi non ottimizzato, chiamato chattiness. Il 𝗚𝗮𝘁𝗲𝘄𝗮𝘆 𝗔𝗴𝗴𝗿𝗲𝗴𝗮𝘁𝗶𝗼𝗻 pattern si occupa di ridurre la chattiness tra il client e i servizi interessati. Questo pattern introduce un gateway centrale che riceve le chiamate dal client e le invia ai singoli servizi. Successivamente li aggrega e invia il risultato in un unico messaggio verso il client.
Ricostruire lo stato: Osservabilità
Uno degli aspetti fondamentali che riguarda qualsiasi sistema è la cosiddetta Osservabilità. In generale, un sistema si definisce osservabile se è possibile ricostruire lo stato interno del sistema osservando la risposta, ovvero l’output. Questo concetto si applica ovviamente anche ai sistemi informatici ed in particolar modo alle architetture a microservizi. Più l’architettura è vasta e coinvolge un numero elevato di servizi, più saranno le interazioni e più risulterà complesso monitorare lo stato interno del sistema. Per garantire l’osservabilità si prendono in esame tre aspetti: le metriche, il trace distribuito e il logging applicativo. Per metriche si intende l’insieme delle funzionalità che monitorano determinativalori, come ad esempio la latenza delle chiamate e il tasso di errore, per valutare lo stato del sistema. Tali funzionalità vengono generalmente fornite dai sistemi che gestiscono l’architettura stessa e si basano spesso sull’utilizzo di specifiche interfacce e sonde che vengono periodicamente monitorate.
Nelle architetture a microservizi o più in generale in quei sistemi nei quali sono presenti chiamate multiple che coinvolgono più entità, come ad esempio web services, uno degli aspetti critici è quello di riuscire a ricostruire la catena di eventi associati ad ogni azione effettuata all’interno dell’architettura. Fondamentale è infatti la possibilità di ricostruire la catena dei messaggi scambiati e degli eventi generati. Generalmente l’approccio è quello di generare un identificativo univoco, inizializzato alla prima invocazione, che verrà passato all’interno del messaggio successivo (ad esempio nell’header del messaggio stesso, se il protocollo utilizzato lo supporta) alle altre entità. Questa modalità è utile soprattutto per correlare i log sfruttando l’identificativo per aggregarli.
Risorse:
https://sharpcoding.medium.com/
Francesco Del Re - engineering87